苹果“套娃”式扩散模型,训练步数减少七成!-比特号,苹果“套娃”式扩散模型,训练步数减少七成!
- 主页 > 资讯
原文来源:量子位

图片来源:由无界AI生成
苹果的一项最新研究,大幅提高了扩散模型在高分辨率图像上性能。
利用这种方法,同样分辨率的图像,训练步数减少了超过七成。
在1024×1024的分辨率下,图片画质直接拉满,细节都清晰可见。

苹果把这项成果命名为MDM,DM就是扩散模型(Diffusion Model)的缩写,而第一个M则代表了套娃(Matryoshka)。
就像真的套娃一样,MDM在高分辨率过程中嵌套了低分辨率过程,而且是多层嵌套。
高低分辨率扩散过程同时进行,极大降低了传统扩散模型在高分辨率过程中的资源消耗。

对于256×256分辨率的图像,在批大小(batch size)为1024的环境下,传统扩散模型需要训练150万步,而MDM仅需39万,减少了超七成。
另外,MDM采用了端到端训练,不依赖特定数据集和预训练模型,在提速的同时依然保证了生成质量,而且使用灵活。

不仅可以画出高分辨率的图像,还能合成16×256²的视频。

有网友评论到,苹果终于把文本连接到图像中了。
那么,MDM的“套娃”技术,具体是怎么做的呢?
整体与渐进相结合
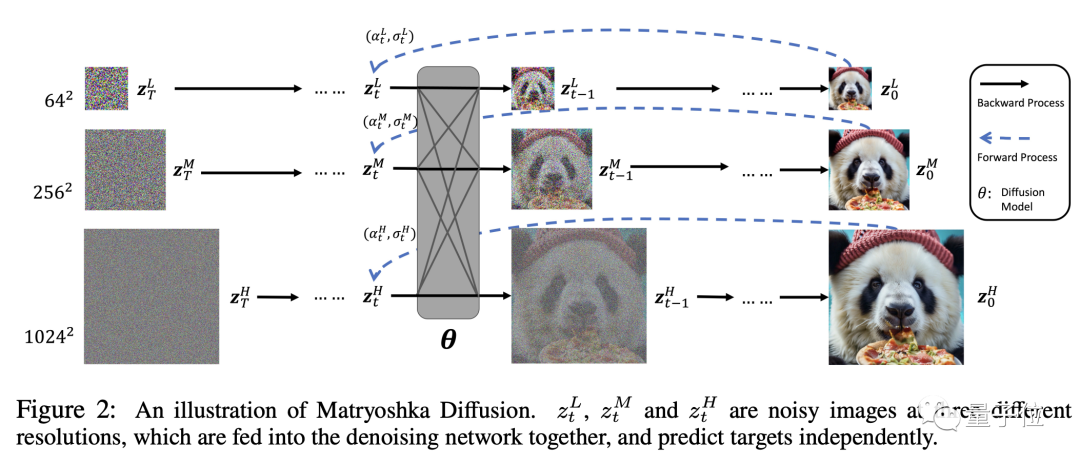
在开始训练之前,需要将数据进行预处理,高分辨率的图像会用一定算法重新采样,得到不同分辨率的版本。
然后就是利用这些不同分辨率的数据进行联合UNet建模,小UNet处理低分辨率,并嵌套进处理高分辨率的大UNet。
通过跨分辨率的连接,不同大小的UNet之间可以共用特征和参数。

MDM的训练则是一个循序渐进的过程。
虽然建模是联合进行的,但训练过程并不会一开始就针对高分辨率进行,而是从低分辨率开始逐步扩大。
这样做可以避免庞大的运算量,还可以让低分辨率UNet的预训练可以加速高分辨率训练过程。
训练过程中会逐步将更高分辨率的训练数据加入总体过程中,让模型适应渐进增长的分辨率,平滑过渡到最终的高分辨率过程。
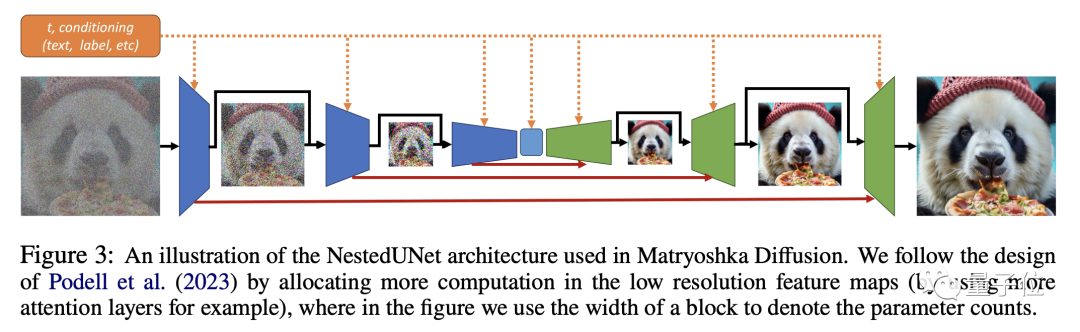
不过从整体上看,在高分辨率过程逐步加入之后,MDM的训练依旧是端到端的联合过程。
在不同分辨率的联合训练当中,多个分辨率上的损失函数一起参与参数更新,避免了多阶段训练带来的误差累积。
每个分辨率都有对应的数据项的重建损失,不同分辨率的损失被加权合并,其中为保证生成质量,低分辨率损失权重较大。
在推理阶段,MDM采用的同样是并行与渐进相结合的策略。
此外,MDM利还采用了预训练的图像分类模型(CFG)来引导生成样本向更合理的方向优化,并为低分辨率的样本添加噪声,使其更贴近高分辨率样本的分布。
那么,MDM的效果究竟如何呢?
更少参数匹敌SOTA
图像方面,在ImageNet和CC12M数据集上,MDM的FID(数值越低效果越好)和CLIP表现都显著优于普通扩散模型。
其中FID用于评价图像本身的质量,CLIP则说明了图像和文本指令之间的匹配程度。
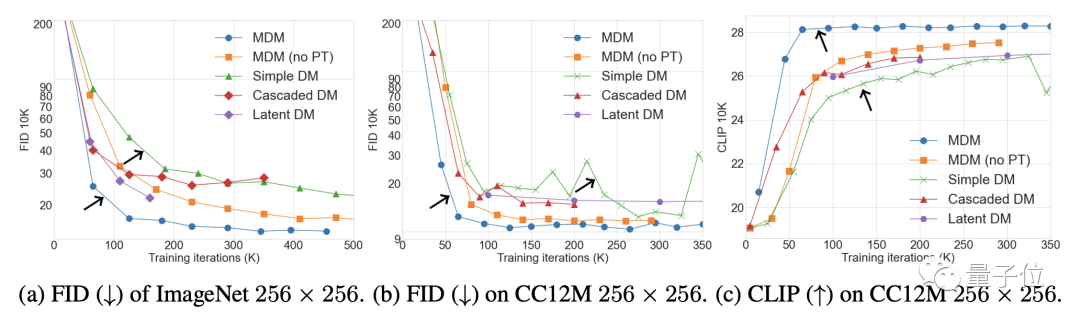
和DALL E、IMAGEN等SOTA模型相比,MDM的表现也很接近,但MDM的训练参数远少于这些模型。
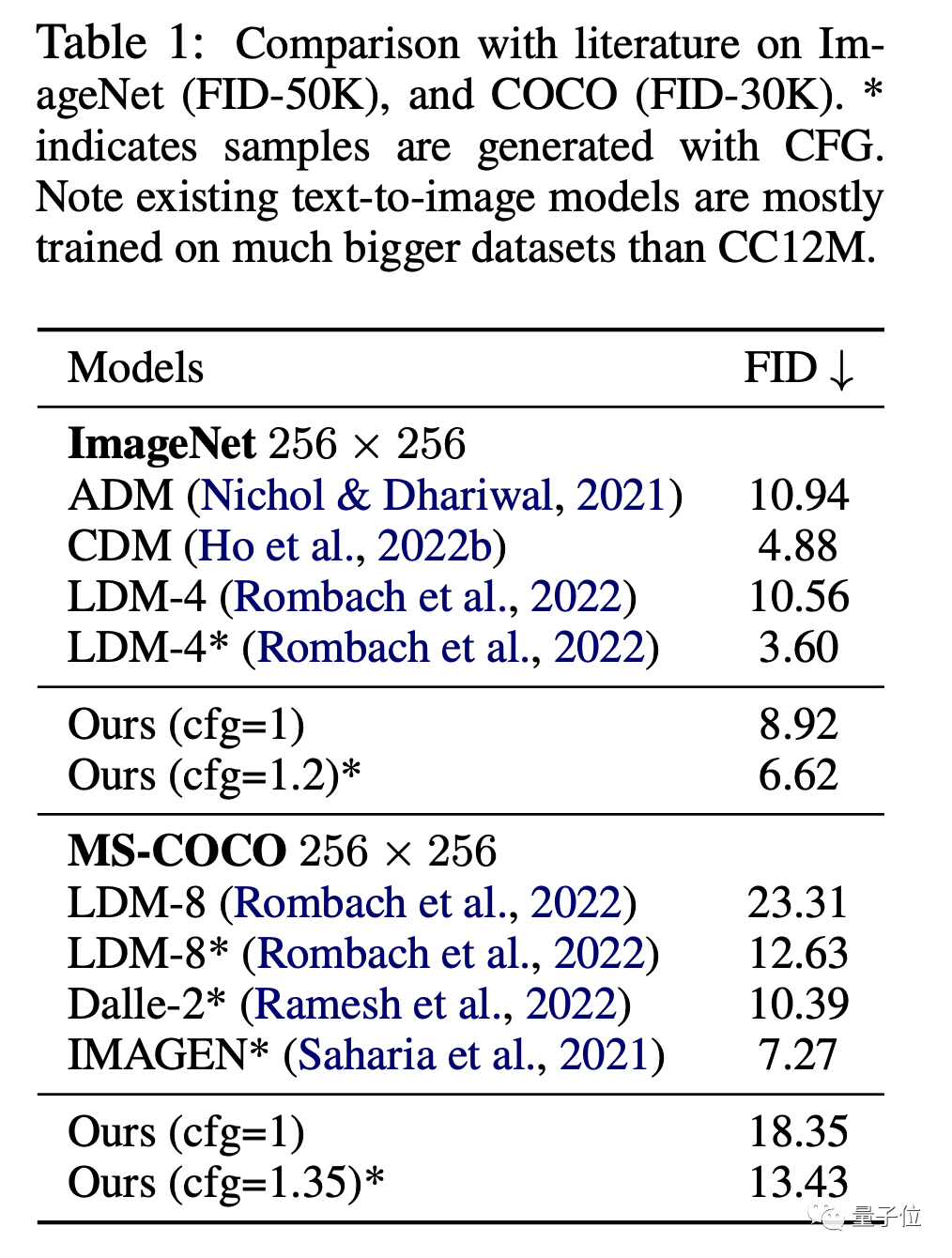
不仅是优于普通扩散模型,MDM的表现也超过了其他级联扩散模型。
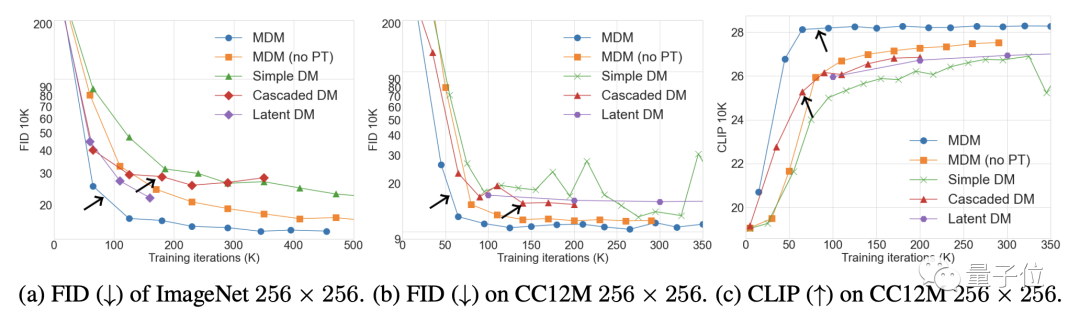
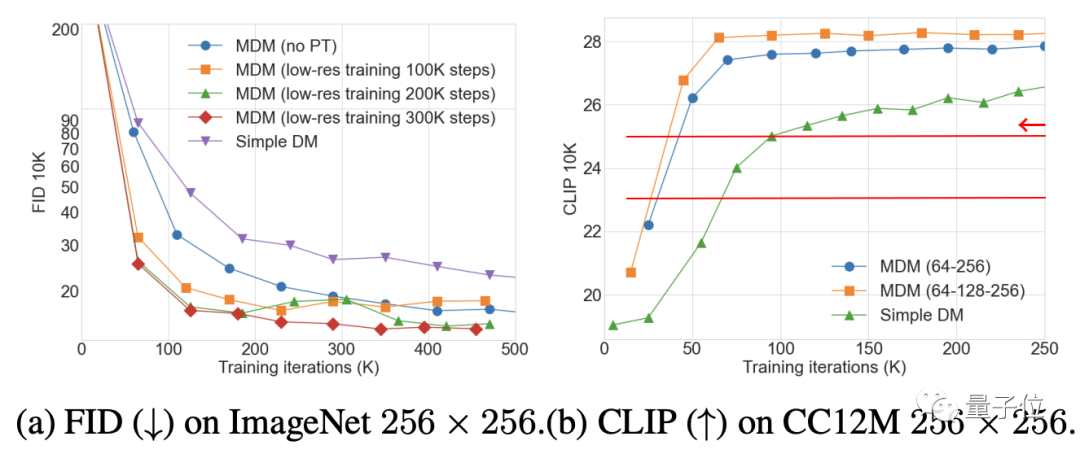
消融实验结果表明,低分辨率训练的步数越多,MDM效果增强就越明显;另一方面,嵌套层级越多,取得相同的CLIP得分需要的训练步数就越少。
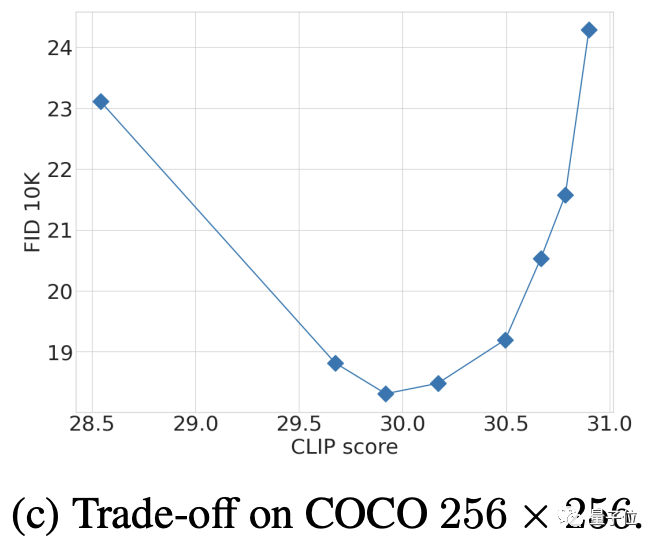
而关于CFG参数的选择,则是一个多次测试后再FID和CLIP之间权衡的结果(CLIP得分高相对于CFG强度增大)。
论文地址:
https://arxiv.org/abs/2310.15111
本文由某某资讯网发布,不代表某某资讯网立场,转载联系作者并注明出处:https://www.yuhuajia.cn/zixun/gjmtvhi8.html
Genesis提交修订后的破产计划以有序关闭和资产清算 « 上一篇 暂无 下一篇 »相关推荐
- 黑天鹅理论的缔造者再次批评加密货币
- 比特币为何涨不上去?
- 摄氏网络致力于就客户资金返还达成协议
- 俄罗斯央行讨论数字卢布与其他国家支付系统的整
- CZ:币安员工数量较一年前翻倍
- LINE旗下加密交易所Bitfront宣布关闭,明年3月底全面结束运营
- AAX副总裁:已从AAX离职,品牌不复存在信任也不复存在
- “WETH FUD”最早传播者:WETH永远不会脱锚
- Coinbase:机构投资者在熊市期间增持数字资产
- 信标链ETH2合约地址质押数达1539万枚ETH
热门文章
-
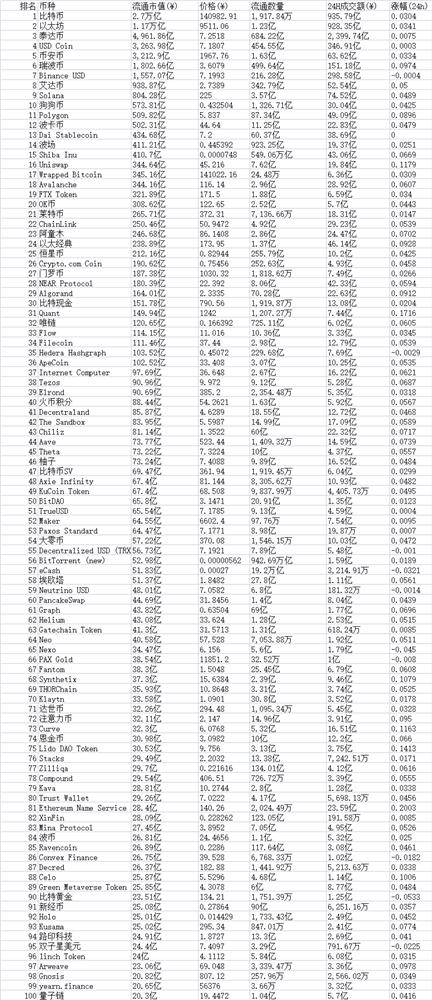
全球虚拟货币前100排名(2023最新版
2022年10月14日
-

维卡币价格表2022(维卡币现在价格)
2022年10月02日
-

π币国际价格(π币市场价格)
2022年09月27日
推荐文章
-

比特币失守16000美元/枚,日内跌幅4
2022年11月14日
-

当前加密货币总市值下跌至1.168万亿美
2023年05月22日
-

币安将尝试禁用在Skyrex上使用过的所
2022年11月14日
-
苹果“套娃”式扩散模型,训练步数减少七成
2023年10月25日
-

Genesis提交修订后的破产计划以有序
2023年10月25日
经典文章
-
全球虚拟货币前100排名(2023最新版
2022年10月14日
-
维卡币价格表2022(维卡币现在价格)
2022年10月02日
-
π币国际价格(π币市场价格)
2022年09月27日
-

中本聪什么时候上线(中本聪币上市时间)
2022年09月24日
-

pi币的未来价值(pi币的未来价值是0,
2022年09月30日
-

钱峰雷可是环球币董事长(环球币董事长)
2022年10月03日
-

2022年pi币官方最新消息(2022年
2022年10月02日
-

派币2022年会上主网吗(2022派币上
2022年10月03日
-

pi币新闻(pi币今天最新消息)
2022年10月05日
-

飞儿币最新消息(fil币今日行情价格)
2022年09月29日
Copyright © 2002-2022 比特号 版权所有 网站备案号:闽ICP备20011267号-4
本文由某某资讯网发布,不代表某某资讯网立场,转载联系作者并注明出处:https://www.yuhuajia.cn/baike/rlcs7h5i.html
Genesis提交修订后的破产计划以有序关闭和资产清算-比特 « 上一篇 ouyiapp.cnm_Dogecoin币交易平台相关推荐
- 环球币公告(中币公告)
- 全国虚拟货币不合规情况(虚拟货币不合规吗)
- 现在什么电视剧最火热(现在什么币最火热)
- 以太坊发行总量多少枚(以太坊共有多少个币)
- 奇亚币价格最新消息(奇亚币历史价格)
- shib最低价格是多少(shib最低价)
- π币怎样交易(π币能交易吗)
- 比特币可以无限生产吗(比特币怎么生产)
- 区块链现在怎么样(现在哪种区块链好)
- 韩国luna官方利好最新消息(luna币有利好吗)
原文来源:量子位
图片来源:由无界AI生成
苹果的一项最新研究,大幅提高了扩散模型在高分辨率图像上性能。
利用这种方法,同样分辨率的图像,训练步数减少了超过七成。
在1024×1024的分辨率下,图片画质直接拉满,细节都清晰可见。
苹果把这项成果命名为MDM,DM就是扩散模型(Diffusion Model)的缩写,而第一个M则代表了套娃(Matryoshka)。
就像真的套娃一样,MDM在高分辨率过程中嵌套了低分辨率过程,而且是多层嵌套。
高低分辨率扩散过程同时进行,极大降低了传统扩散模型在高分辨率过程中的资源消耗。
对于256×256分辨率的图像,在批大小(batch size)为1024的环境下,传统扩散模型需要训练150万步,而MDM仅需39万,减少了超七成。
另外,MDM采用了端到端训练,不依赖特定数据集和预训练模型,在提速的同时依然保证了生成质量,而且使用灵活。
不仅可以画出高分辨率的图像,还能合成16×256²的视频。
有网友评论到,苹果终于把文本连接到图像中了。
那么,MDM的“套娃”技术,具体是怎么做的呢?
整体与渐进相结合
在开始训练之前,需要将数据进行预处理,高分辨率的图像会用一定算法重新采样,得到不同分辨率的版本。
然后就是利用这些不同分辨率的数据进行联合UNet建模,小UNet处理低分辨率,并嵌套进处理高分辨率的大UNet。
通过跨分辨率的连接,不同大小的UNet之间可以共用特征和参数。
MDM的训练则是一个循序渐进的过程。
虽然建模是联合进行的,但训练过程并不会一开始就针对高分辨率进行,而是从低分辨率开始逐步扩大。
这样做可以避免庞大的运算量,还可以让低分辨率UNet的预训练可以加速高分辨率训练过程。
训练过程中会逐步将更高分辨率的训练数据加入总体过程中,让模型适应渐进增长的分辨率,平滑过渡到最终的高分辨率过程。
不过从整体上看,在高分辨率过程逐步加入之后,MDM的训练依旧是端到端的联合过程。
在不同分辨率的联合训练当中,多个分辨率上的损失函数一起参与参数更新,避免了多阶段训练带来的误差累积。
每个分辨率都有对应的数据项的重建损失,不同分辨率的损失被加权合并,其中为保证生成质量,低分辨率损失权重较大。
在推理阶段,MDM采用的同样是并行与渐进相结合的策略。
此外,MDM利还采用了预训练的图像分类模型(CFG)来引导生成样本向更合理的方向优化,并为低分辨率的样本添加噪声,使其更贴近高分辨率样本的分布。
那么,MDM的效果究竟如何呢?
更少参数匹敌SOTA
图像方面,在ImageNet和CC12M数据集上,MDM的FID(数值越低效果越好)和CLIP表现都显著优于普通扩散模型。
其中FID用于评价图像本身的质量,CLIP则说明了图像和文本指令之间的匹配程度。
和DALL E、IMAGEN等SOTA模型相比,MDM的表现也很接近,但MDM的训练参数远少于这些模型。
不仅是优于普通扩散模型,MDM的表现也超过了其他级联扩散模型。
消融实验结果表明,低分辨率训练的步数越多,MDM效果增强就越明显;另一方面,嵌套层级越多,取得相同的CLIP得分需要的训练步数就越少。
而关于CFG参数的选择,则是一个多次测试后再FID和CLIP之间权衡的结果(CLIP得分高相对于CFG强度增大)。
论文地址:
https://arxiv.org/abs/2310.15111
本文由某某资讯网发布,不代表某某资讯网立场,转载联系作者并注明出处:https://www.yuhuajia.cn/zixun/gjmtvhi8.html
Genesis提交修订后的破产计划以有序关闭和资产清算 « 上一篇 暂无相关推荐
- 黑天鹅理论的缔造者再次批评加密货币
- 比特币为何涨不上去?
- 摄氏网络致力于就客户资金返还达成协议
- 俄罗斯央行讨论数字卢布与其他国家支付系统的整
- CZ:币安员工数量较一年前翻倍
- LINE旗下加密交易所Bitfront宣布关闭,明年3月底全面结束运营
- AAX副总裁:已从AAX离职,品牌不复存在信任也不复存在
- “WETH FUD”最早传播者:WETH永远不会脱锚
- Coinbase:机构投资者在熊市期间增持数字资产
- 信标链ETH2合约地址质押数达1539万枚ETH
免责声明:本文为转载,非本网原创内容,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
如有疑问请发送邮件至:bangqikeconnect@gmail.com